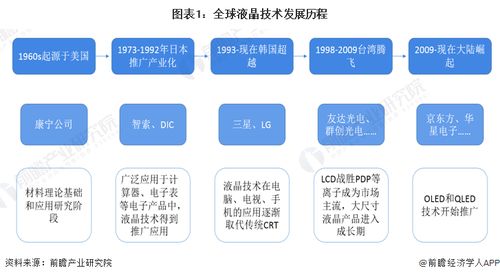
2025版Java面试宝典 微服务架构下的数据处理服务深度解析与实战答案
随着微服务架构的持续演进,数据处理服务作为核心支撑组件,其设计与实现已成为高级Java开发者面试中的高频考点。本文聚焦2025年技术趋势,系统梳理微服务场景下数据处理服务的关键问题、核心模式与最佳实践,助你从容应对面试挑战。
一、核心概念与架构模式
1. 数据处理服务的定位
在微服务生态中,数据处理服务专责于数据的加工、转换、聚合与供给。它不同于基础的数据存储服务(如数据库服务),更侧重于业务逻辑相关的数据操作,是连接数据存储与业务应用的桥梁。其核心价值在于解耦、复用与性能优化。
- 核心架构模式
- CQRS(命令查询职责分离):将写模型(命令)与读模型(查询)分离,允许独立扩展。面试需掌握其适用场景(如读写负载差异大、数据模型复杂)及与Event Sourcing的搭配使用。
- Saga模式:用于管理跨多个微服务的分布式事务。需熟练掌握编排(Orchestration)与协同(Choreography)两种实现方式的优劣,以及如何通过补偿事务保证最终一致性。
- 事件驱动架构:通过消息中间件(如Kafka, Pulsar)实现服务间松耦合通信。重点理解事件溯源、事件通知与事件携带状态转移的区别。
二、关键技术栈与面试答案要点
- 数据同步与一致性
- 问题:“如何保证微服务间数据最终一致性?”
- 答案要点:
- 异步消息:通过可靠消息队列(确保幂等性)传播数据变更事件。
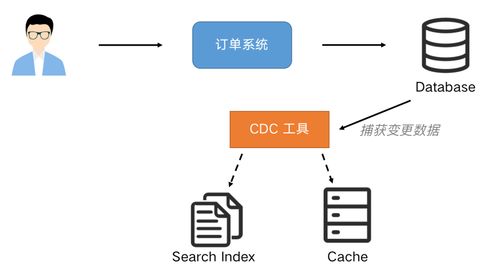
- CDC(变更数据捕获):使用Debezium等工具监听数据库日志,低侵入地捕获并发布变更。
- 补偿机制:设计可回滚的Saga流程或基于状态的补偿作业。
- 版本号与乐观锁:在聚合根或关键实体中采用版本控制,避免并发更新冲突。
- 缓存策略与设计
- 问题:“如何处理缓存与数据库的一致性问题?”
- 答案要点:
- 策略选择:详述Cache-Aside、Read/Write Through、Write Behind的适用场景。
- 失效与更新:优先采用“先更新数据库,再删除缓存”策略,并结合延迟双删降低不一致窗口。
- 多级缓存:本地缓存(Caffeine) + 分布式缓存(Redis)的组合方案,注意本地缓存的过期同步问题。
- 热点缓存:应对突发流量,采用本地缓存+Redis+锁/队列机制防止缓存击穿。
- 批量与流式处理
- 问题:“微服务中如何实现近实时数据聚合?”
- 答案要点:
- 流处理框架:Flink或Kafka Streams进行窗口(滚动、滑动、会话)计算与状态管理。
- Lambda/Kappa架构:理解其演变,当前趋势更倾向于简化的Kappa架构,统一用流处理层处理实时与回溯分析。
- 物化视图:在查询侧使用数据库物化视图或Elasticsearch索引,通过CDC实时更新。
- API设计与性能优化
- 问题:“设计一个高性能的数据查询API,需聚合多个服务的数据。”
- 答案要点:
- BFF(Backend for Frontend)模式:为特定前端定制聚合接口,避免客户端多次调用。
- GraphQL应用:在复杂数据获取场景下,由前端精确指定所需字段,减少过度获取与多次请求。
- 异步与非阻塞:使用CompletableFuture或Reactive编程(Project Reactor)并行调用下游服务,优化响应时间。
- 分页与游标:大数据集查询必须支持高效分页,避免使用
OFFSET LIMIT,推荐基于索引或创建时间的游标分页。
三、2025年新趋势与面试前瞻
- 数据网格(Data Mesh):作为新兴范式,强调数据的产品化、领域所有权与自助式基础设施。面试官可能探讨如何将传统集中式数据平台重构为去中心化的数据网格,以及数据产品团队与数据平台团队的职责划分。
- 实时数仓与湖仓一体:数据处理服务与实时数仓(如Apache Doris, StarRocks)的边界融合。需了解如何将微服务产生的实时事件流直接写入实时数仓,并支持即席查询与分析。
- AI集成与向量数据处理:随着AIGC应用普及,数据处理服务需集成向量数据库(如Milvus, Weaviate)以支持 embedding 的存储与相似性检索,为智能推荐、搜索提供支撑。
- Serverless数据处理:利用云函数(如AWS Lambda, 阿里云FC)实现事件触发的、无状态的数据处理管道,实现极致弹性与成本优化。
四、实战场景与问题排查
面试中常会给出一个具体场景(如“电商订单履约后的数据分析延迟”),要求你设计解决方案或排查问题。应对思路:
- 明确需求:区分是实时监控、离线报表还是即席查询。
- 绘制数据流图:从源头(业务服务)到终点(数据产品),识别瓶颈环节(如消息积压、Join性能差)。
- 选择工具链:根据延迟要求(毫秒、秒、分钟级)选择流、批或HTAP引擎。
- 保障可靠性:考虑去重、顺序性、故障恢复与监控告警。
****:应对微服务数据处理服务的面试,关键在于深入理解分布式系统原理,掌握主流技术栈的选型与折衷,并展现出对技术趋势的敏锐洞察。将上述知识点内化为自己的架构思维,结合过往项目经验具体阐述,方能脱颖而出。
如若转载,请注明出处:http://www.baiying101.com/product/74.html
更新时间:2026-06-19 20:12:08