Flink SQL CDC 现代实时数据处理的终极武器
在当今数据驱动的时代,企业对于实时数据处理能力的需求日益增长。无论是实时监控、实时报表、实时推荐还是异常检测,都要求系统能够以极低的延迟处理源源不断的数据流。在这一背景下,Apache Flink 凭借其强大的流处理能力脱颖而出,而结合其 SQL 语法与 Change Data Capture(CDC)技术的 Flink SQL CDC,更是被广泛认为是构建现代数据处理服务的“终极武器”。
一、 什么是 Flink SQL CDC?
Flink SQL CDC 是 Apache Flink 社区推出的一种基于 SQL 和 Change Data Capture 的流式数据处理方案。其核心思想是:
- CDC(变更数据捕获):实时捕获数据库(如 MySQL, PostgreSQL, MongoDB)中数据表的插入(INSERT)、更新(UPDATE)和删除(DELETE)操作,并将其作为数据流输出。这解决了传统批处理无法感知数据实时变化的问题。
- Flink SQL:用户可以使用熟悉的标准 SQL 语句来定义对这些数据流的处理逻辑,例如过滤、聚合、关联等,无需编写复杂的 Java/Scala 代码,极大降低了开发门槛。
- 无缝集成:它将两者深度融合,使得用户能够像查询静态表一样,用 SQL 实时查询和分析动态变化的数据库数据。
二、 为何是“终极武器”?
相比于传统的数据集成与处理方案,Flink SQL CDC 在构建数据处理服务时展现出无可比拟的优势:
1. 极致的开发效率与低门槛
传统流处理开发需要理解复杂的API、状态管理和时间语义。而 Flink SQL CDC 让数据工程师和数据分析师能够直接使用 SQL——这个领域内最通用的语言,来定义实时数据管道。一条简单的 CREATE TABLE 语句即可对接 CDC 数据源,再通过 INSERT INTO 将处理结果输出到目标库,开发周期从“天级”缩短到“小时级”。
2. 完整的流式语义与精确一致性
Flink 提供了业界领先的精确一次(Exactly-Once)语义保证。在 CDC 场景下,这意味着能够确保从源数据库捕获的每一条变更记录,在经历复杂的流处理逻辑后,都能被准确地处理一次并输出到目标系统,杜绝了数据重复或丢失,为关键业务提供了坚实的数据一致性基础。
3. 全增量一体的无缝读取
在首次启动时,Flink SQL CDC 连接器会先对源表进行一次性快照(全量读取),然后自动无缝切换到监听 binlog(增量读取)。这种“全量+增量”的同步模式,使得初始化历史数据和实时监听变更可以统一在一个作业中完成,简化了架构。
4. 强大的流式关联能力
实时数仓和数据分析中常见的“维表关联”场景,在 Flink SQL CDC 中变得异常简单。无论是将实时订单流与通过 CDC 实时变化的商品维度表进行关联(动态维度表),还是将两个来自不同数据库的 CDC 流进行实时 JOIN,都能轻松实现,确保关联结果始终反映最新的数据状态。
5. 简化的架构与降低运维成本
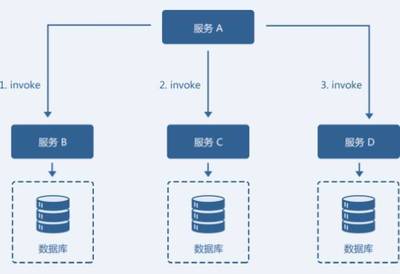
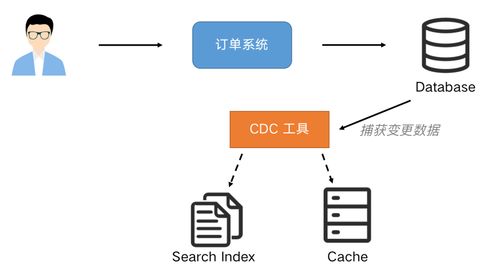
使用 Flink SQL CDC 之前,一个典型的实时数据同步链路可能涉及 Canal/Debezium(捕获变更) + Kafka(消息队列) + Flink Job(消费处理)。现在,Flink SQL CDC 内置了 CDC 连接器,可以直接对接数据库,将多组件架构简化为统一的 Flink 作业,减少了中间环节,降低了运维复杂度和故障点。
三、 典型应用场景
- 实时数据同步与入湖入仓:将 OLTP 数据库的数据实时、准确地同步到数据湖(Iceberg/Hudi)或数据仓库(ClickHouse, StarRocks)中,构建实时数仓。
- 实时物化视图:基于源表变更,在目标端实时维护一个预聚合或预关联的物化视图,供 BI 工具进行亚秒级查询。
- 数据库双活与多活:在不同地域或数据中心的数据库之间进行双向或单向的实时数据同步,保障业务连续性。
- 实时监控与告警:实时计算业务指标(如交易额、用户活跃度),并与阈值对比,即时触发告警。
- 搜索索引实时更新:将数据库的变更实时推送到 Elasticsearch 或 Solr 中,保证搜索结果的即时性。
四、 最佳实践与展望
要发挥这把“终极武器”的最大威力,需要注意:
- 合理规划资源:CDC 读取尤其是全量阶段可能对源库有压力,建议在业务低峰期启动,或调整读取并行度。
- 注意状态管理:对于无限流上的聚合操作,要设置合理的状态生存时间(TTL),防止状态无限膨胀。
- 利用 Flink 生态:将处理结果写入到 Kafka、HBase、Redis 等多种 Sink,或利用 Flink ML 进行实时机器学习。
随着 Flink CDC 社区的发展,其连接器种类日益丰富(已支持十多种数据库),性能与稳定性持续优化。Flink SQL CDC 将进一步与流批一体、数据湖集成等方向深度结合,成为企业构建统一、高效、实时的数据处理服务的核心基石。
总而言之,Flink SQL CDC 通过将强大的流处理引擎、简易的 SQL 接口和精准的数据变更捕获技术三者合一,成功地将实时数据处理的复杂性和开发成本降至新低。对于追求敏捷、实时和准确的数据团队而言,它无疑是一把不可多得的“终极武器”,正引领着数据处理服务进入一个全新的时代。
如若转载,请注明出处:http://www.baiying101.com/product/84.html
更新时间:2026-06-19 06:52:44