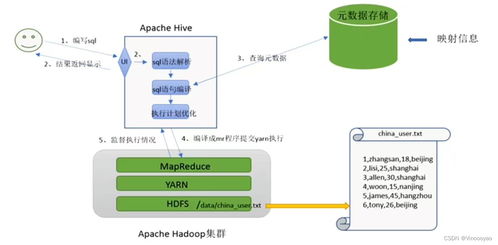
数据湖 剑指下一代数据处理服务的数据仓库革新者
在数字化转型浪潮中,数据已成为驱动企业决策与创新的核心资产。传统数据仓库因其严谨的结构化模型和历史积淀,在稳定报告和商业智能分析方面功不可没。面对海量、多源、高速的异构数据(如日志、IoT传感器数据、社交媒体流、图像视频),其固有的模式写入(Schema-on-Write)范式显得力不从心,流程僵化且成本高昂。正是在此背景下,数据湖(Data Lake) 应运而生,以其开放、灵活和可扩展的特性,正被业界视为剑指下一代数据仓库的颠覆性架构,并重塑着数据处理服务的格局。
数据湖的核心思想是“先存储,后处理”。它将来自各种源头(包括结构化、半结构化和非结构化数据)的原始数据,以其原生格式不加处理或仅进行最低限度的转换,集中存储在一个可大规模扩展的存储库中(通常基于对象存储如Amazon S3、Azure Data Lake Storage或HDFS)。这种模式读取(Schema-on-Read) 的方式,赋予了数据前所未有的灵活性。业务用户、数据科学家和分析师可以按需访问原始数据,根据具体的分析场景定义数据结构和转换逻辑,极大地缩短了从数据获取到洞察的时间周期,并支持探索性分析、机器学习、实时分析等高级用例。
相较于传统数据仓库,数据湖的“剑指”优势体现在多个维度:
- 成本与可扩展性:利用廉价的云对象存储,数据湖可以经济高效地存储海量数据,其近乎无限的扩展能力轻松应对数据量的爆炸式增长。
- 数据民主化与灵活性:打破了数据必须预先建模才能使用的壁垒,使得原始数据能够被更广泛的团队访问和利用,支持快速试错和创新。
- 支持高级分析:作为机器学习、人工智能和实时流处理的理想数据源,数据湖为预测性分析和复杂的数据产品开发提供了肥沃的土壤。
- 避免数据孤岛:通过集中存储所有原始数据,数据湖有助于构建企业级的统一数据视图,减少数据移动和冗余。
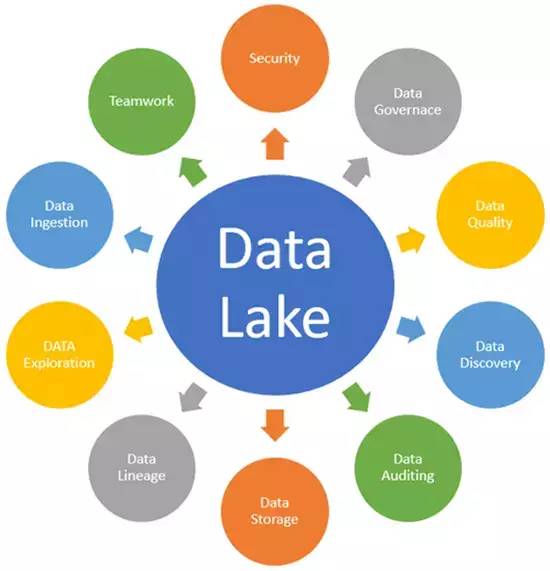
数据湖并非完美无缺。其最大的挑战在于,若无妥善治理,极易退化为无人管理的“数据沼泽”——数据质量低下、难以发现、安全风险高、价值无法释放。因此,下一代数据处理服务的核心任务,正是围绕数据湖构建强大的治理、安全、元数据管理和处理能力。
这催生了湖仓一体(Lakehouse) 架构的兴起,它旨在融合数据湖的灵活性与数据仓库的事务管理、数据质量和性能优势。现代数据处理服务(如Databricks、Snowflake、BigQuery等)正积极拥抱这一范式,提供统一的服务层,使得在同一个数据平台上既能执行灵活的数据探索和机器学习,也能运行高性能的SQL分析和严格的商业智能报告。
数据湖及其演进形态将继续引领数据处理服务的变革。其发展方向将聚焦于:
- 智能化治理:利用AI/ML自动进行数据分类、质量检测、血缘追踪和策略执行。
- 实时化融合:无缝集成流批处理,支持从实时事件中即时获取洞察。
- 简化与一体化:通过统一的SQL接口、自动化运维和Serverless计算,降低使用门槛,让用户更专注于数据价值本身。
数据湖已不仅仅是技术的迭代,它代表了一种面向未来的数据管理哲学——以原始数据为中心,通过强大、智能的数据处理服务赋能业务。它并非要完全取代数据仓库,而是通过融合与进化,共同构建起更敏捷、更强大、更具成本效益的下一代企业数据基石。在这场变革中,谁能更好地驾驭数据湖,构建卓越的数据处理服务,谁就将在数据驱动的竞争中赢得先机。
如若转载,请注明出处:http://www.baiying101.com/product/85.html
更新时间:2026-06-19 13:52:49