数据治理架构中的数据处理服务 核心组件、挑战与最佳实践
在当今数据驱动的商业环境中,一个健全的数据治理架构是企业实现数据资产价值最大化的基石。而数据处理服务,作为该架构中承上启下的关键执行层,其设计与实施的质量直接决定了数据治理的成效。本文旨在对数据治理架构中的数据处理服务进行与分析,探讨其核心角色、面临的挑战以及未来的发展趋势。
一、数据处理服务在数据治理架构中的定位与核心组件
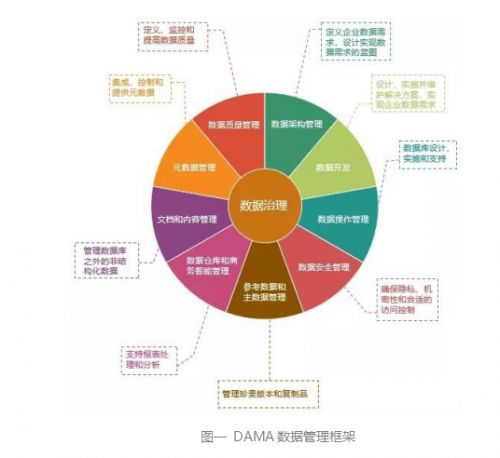
数据治理架构通常分为战略层、组织层、策略层和执行层。数据处理服务主要位于执行层,是具体落实数据质量、安全、生命周期等治理策略的技术实现载体。它并非单一工具,而是一个集成了多种技术和流程的服务集合,主要包括:
- 数据集成与摄取服务:负责从异构的源系统(如业务数据库、日志文件、物联网设备、第三方API)中抽取数据,并进行清洗、转换和加载(ETL/ELT),为后续处理提供高质量、一致的数据源。这是确保数据“可用”的第一步。
- 数据质量管控服务:在数据处理流水线中嵌入质量检查规则。通过实时或批量的方式,对数据的完整性、准确性、一致性、唯一性和时效性进行监控、评估与修复,是保障数据“可信”的核心。
- 主数据与参考数据管理服务:确保关键业务实体(如客户、产品、供应商)数据在全企业范围内的统一、准确和权威。该服务维护“黄金记录”,为所有分析应用提供一致的主数据视图。
- 元数据管理服务:捕获、存储和管理关于数据的技术元数据(如数据结构、血缘关系)和业务元数据(如业务定义、负责人)。它为数据处理过程提供上下文,支持影响分析、血缘追踪和合规审计。
- 数据安全与隐私服务:在数据处理过程中实施加密、脱敏、访问控制和数据遮蔽策略,确保敏感数据在存储、传输和使用环节符合法律法规(如GDPR、个保法)与内部安全政策。
- 数据处理编排与调度服务:负责协调复杂的数据处理流水线,管理任务之间的依赖关系、执行顺序和资源调度,确保数据处理作业高效、可靠地运行。
二、数据处理服务面临的主要挑战
尽管技术不断进步,但在实践中,构建和运维高效的数据处理服务仍面临诸多挑战:
- 复杂度与规模:数据源激增、数据量爆炸式增长、处理逻辑日益复杂,对服务的可扩展性、性能和稳定性提出了极高要求。
- 实时性需求:从传统的T+1批处理向实时、准实时流处理演进,要求架构能够支持低延迟的数据处理与服务。
- 技术栈异构:企业往往存在多种数据处理技术和平台(如Hadoop生态、云数仓、流处理引擎),整合与管理这些异构环境是一大难题。
- 成本控制:计算、存储资源的成本,特别是云上成本,需要精细化的管理和优化。
- 组织与流程协同:数据处理服务的高效运转不仅依赖技术,更需要与数据治理的组织、流程紧密配合。跨部门协作不畅是常见的失败原因。
三、发展趋势与最佳实践
为应对上述挑战,数据处理服务的发展呈现出以下趋势,并形成了一些行业最佳实践:
- 云原生与平台化:采用容器化、微服务、Serverless等云原生技术构建数据处理平台,实现弹性伸缩、高可用和敏捷部署。平台化思维有助于统一技术栈、降低运维复杂度。
- 批流一体化:借助Apache Flink、Spark Structured Streaming等框架,构建统一的批流融合处理架构,用同一套代码逻辑处理历史和实时数据,简化开发运维。
- DataOps的兴起:将DevOps理念引入数据领域,强调数据处理流程的自动化、监控、协作与快速迭代。通过CI/CD管道实现数据处理作业的自动化测试与部署,提升交付效率和质量。
- 主动与智能化的数据质量管理:利用机器学习和人工智能技术,实现异常模式的自动检测、数据质量的预测性维护以及数据清洗规则的智能推荐。
- 隐私增强计算(PEC)的应用:在数据处理环节引入联邦学习、安全多方计算、差分隐私等技术,实现在不暴露原始数据的前提下进行联合分析,平衡数据价值挖掘与隐私保护。
- 成本与性能的精细优化:通过数据分层存储、计算资源自动伸缩、作业性能剖析与优化等手段,实现数据处理成本效益的最大化。
四、
数据处理服务是数据治理从蓝图走向现实的关键工程化环节。一个设计优良的数据处理服务体系,能够高效、可靠、安全地将原始数据转化为可信、可用、有价值的数据资产,从而赋能数据分析、人工智能应用和业务决策。随着技术的演进和需求的深化,数据处理服务必将朝着更智能、更融合、更自动化、更安全合规的方向持续发展。企业需要将其置于数据治理战略的核心位置进行规划和建设,方能真正释放数据潜能,赢得竞争优势。
如若转载,请注明出处:http://www.baiying101.com/product/83.html
更新时间:2026-06-19 05:46:33